Author: NashQ, Celestia Researcher
Original Title: Redefining Sequencers: Understanding the Aggregator and the Header Producer
Translation: Faust, Geek Web3
Translator’s Note: In order to make the Rollup model easier to understand and analyze, Celestia researcher NashQ divided the Rollup sequencer into two logical entities: the aggregator and the header producer. At the same time, he divided the transaction ordering process into three logical steps: inclusion, ordering, and execution.
- Binance Launches LianGuaid’s New Project Arkham Practical Tutorial and Valuation Analysis
- Inventory of OP Stack’s star projects and airdrop interaction strategies
- Kakarot Exploring the EVM Compatibility of Starknet
With this analytical approach, the 6 important variants of Sovereign Rollup become clearer and easier to understand. NashQ discusses in detail the review resistance and activity of different Rollup variants, as well as explores the minimum configuration of nodes for each Rollup variant to achieve trustless state (i.e., what types of nodes Rollup users need to run at least).
Although this article analyzes Rollup from the perspective of Celestia, which is different from the way the Ethereum community analyzes the Rollup model, considering the many similarities between Ethereum Rollup and Celestia Sovereign Rollup, as well as the increasing influence of the latter, this article is also extremely worth reading for Ethereum enthusiasts.

What is Rollup?
Rollup is a blockchain that publishes its “transaction data” to another blockchain and inherits its consensus and data availability.
Why did I intentionally use the term “transaction data” instead of “block”? This is because there is a difference between rollup blocks and rollup data, and the simplest rollup only requires rollup data as in the first variant described below.
A Rollup block is a data structure that represents the blockchain ledger at a certain block height. A Rollup block consists of rollup data and rollup header. The rollup data can be a batch of transactions or state changes between batches of transactions.
Variant 1: Pessimistic Rollup / Based Rollup
The simplest way to build Rollup is to have users publish transactions to another blockchain, which we call the consensus and data availability layer (DA-Layer), or simply the DA layer below.
In the first variant of Rollup that I’m going to introduce, the nodes in the Rollup network must re-execute the Rollup transactions contained in the DA layer to verify the final state of the ledger. This is the pessimistic Rollup!
Pessimistic Rollup is a type of Rollup that only supports full nodes, which need to re-execute all the transactions contained in the Rollup ledger to check their validity.

But in this case, who acts as the sequencer of Rollup, the Sequencer? In fact, other than the full nodes of Rollup, no entity has executed the transactions contained in the Rollup ledger. Generally, the sequencer aggregates transaction data and generates a Rollup header. But the pessimistic Rollup mentioned above does not have a Rollup header!
In order to facilitate the discussion, we can divide the sequencer into two logical entities: the aggregator and the header generator. To generate a Rollup Header, transactions must be executed first, completing the state transition and then calculating the corresponding Header. However, for the aggregator, it does not need to complete the state transition and can proceed to the aggregation step.
Sequencing is the process of “aggregation + creating Rollup Header”.
Aggregation is the step of batch packaging transaction data into a batch. A batch generally contains many transactions (translator’s note: the batch refers to the part of the Rollup block data other than the Header).
The header generation step is the process of creating the Rollup Header. The Rollup Header is metadata about the Rollup block, which at least includes a commitment to the transaction data in the block (translator’s note: here, “commitment” refers to the commitment to the correctness of the transaction processing results).

From the above perspective, we can see who plays the role of each component of Rollup. Let’s first look at the aggregator. In the pessimistic Rollup mentioned earlier, there is no header generation process, and users directly publish transactions to the DA layer, which means that the DA layer network essentially acts as the aggregator.
Therefore, the pessimistic Rollup delegates the aggregation step to the Rollup variant of the DA layer, and it does not have a sequencer. Sometimes this type of Rollup is referred to as a “based rollup”.
Based Rollup has the same censorship resistance and liveliness (a measure of the system’s feedback speed to user requests) as the DA layer. If users of this type of Rollup want to achieve a state of minimal trust (closest to Trustless), they need to run at least one light node of the DA layer network and a full node of the Rollup network.
Variation 2: Pessimistic Aggregation Using a Shared Aggregator

Let’s discuss pessimistic aggregation using a shared aggregator. This idea was proposed by Evan Forbes in his forum post on shared sequencer design. The key assumption is that the shared sequencer is the only legitimate way to order transactions. Evan explains the benefits of the shared sequencer as follows:
“In order to achieve a user experience equivalent to Web2, the shared sequencer can provide fast-generated Soft Commitments (not very reliable guarantees). These Soft Commitments provide some guarantees about the final transaction order (i.e., the commitment that the transaction order will not change), and allow the steps of updating the Rollup ledger state to be performed in advance (but it is not yet finalized).
Once the Rollup block data is confirmed to be published to the base layer (referring to the DA layer here), the update of the Rollup ledger state is finalized.”

The above variant of Rollup still belongs to the category of pessimistic Rollup, because there are only full nodes in this type of Rollup system, and no light nodes. Each Rollup node needs to execute all transactions to ensure the validity of the ledger state update. Because this type of Rollup does not have light nodes, it does not require a Rollup Header or a header generator. (Translator’s note: generally speaking, a light node of a blockchain does not need to synchronize the entire block, it only needs to receive the block header.)
Due to the absence of the Rollup Header generation step, the shared sequencer of the Rollup mentioned above does not need to execute transactions for state updates (precondition for generating the Header), but only includes the process of aggregating transaction data. Therefore, I prefer to call it a shared aggregator.
In this variant, Rollup users, under the principle of minimal trust, need to run at least a DA-layer light node + a light node of the shared aggregator network + a Rollup full node.
At this point, it is necessary to use the light node of the shared aggregator network to verify the published aggregator header (which refers to the non-Rollup Header). As mentioned above, the shared aggregator is responsible for the transaction ordering work, and it includes a cryptographic commitment in the published aggregator header, corresponding to the Batch it publishes on the DA layer.
In this way, the operator of the Rollup node can confirm that the Batch it receives from the DA layer is created by the shared aggregator, not someone else.
- Inclusion is the process of including transactions in the blockchain.
- Ordering is the process of arranging transactions in a specific order in the blockchain.
- Execution is the process of processing transactions in the blockchain and completing state updates.
Since the shared aggregator is responsible for the inclusion and ordering work, the censorship resistance of the Rollup depends on it.
If we assume that L_ss is the liveness of the shared aggregator and L_da is the liveness of the DA layer, then the liveness of this Rollup model is L = L_da && L_ss. In other words, if there is a liveness failure in either of the two parts, the Rollup will also have a liveness failure.
For simplicity, I will consider liveness as a boolean value. If the shared aggregator fails, the Rollup cannot continue to operate. If the DA layer network fails, the shared aggregator can continue to provide Soft Commitment for Rollup blocks. However, at this time, the various properties of the Rollup will be completely dependent on the shared aggregator network, which often falls far short of the original DA layer.
Let’s continue to discuss the censorship resistance of the above-mentioned Rollup scheme:
In this scheme, the DA layer cannot censor specific transactions (translator’s note: transaction censorship often involves refusing to include certain transactions on the chain), it can only conduct transaction censorship against the entire transaction batch Batch submitted by the shared aggregator (refusing to include a certain Batch in the DA layer).
However, according to the workflow of the Rollup, the shared aggregator has already completed the transaction ordering when submitting the transaction batch Batch to the DA layer, and the order between different batches has also been determined. Therefore, this transaction censorship in the DA layer, besides delaying the finality confirmation of the Rollup ledger, has no other effect.
In summary, I believe that the focus of censorship resistance is to ensure that no entity can control or manipulate the flow of information within the system, while liveness involves maintaining the functionality and availability of the system, even in the presence of network interruptions and adversarial behavior. Although this conflicts with the current mainstream academic definition, I will still use the concept definition I have outlined.
Variation 3: Pessimistic Rollup based on Based Rollup and Shared Aggregator

Although the shared aggregator brings benefits to users and the community, we should avoid relying too much on it and allow users to withdraw from the shared aggregator to the DA layer. We can combine the two Rollup variations introduced earlier, allowing users to directly submit transactions to the DA layer while using the shared aggregator.
We assume that the final Rollup transaction sequence depends on the transaction sequence submitted by the shared aggregator and the Rollup transactions directly submitted by users in the DA layer blocks. We call this the Rollup’s fork selection rule.

Aggregation is divided into two steps here. First, the shared aggregator plays a role in aggregating some transactions. Then, the DA layer can aggregate the batches submitted by the shared aggregator and the transactions directly submitted by users.
The censorship resistance analysis at this point is more complex. DA layer network nodes may review the batch submitted by the shared aggregator before the next DA layer block is created. After knowing the transaction data in the batch, DA layer nodes can extract MEV value, initiate frontrunning transactions with their own accounts on the Rollup network, and include them in the DA layer block before including the batch submitted by the Rollup shared aggregator.
Obviously, the transaction order guaranteed by soft commitment in the third variation of Rollup is more fragile than the second variation mentioned earlier. In this case, the shared aggregator hands over the MEV value to the DA layer nodes. In this regard, I suggest readers watch lectures on the profitable exploitation of MEV through censorship.
There are already some design proposals to reduce the ability of DA layer network nodes to execute such MEV transactions, such as the “recomposition window” feature, which delays the execution of transactions directly submitted by Rollup network users to the DA layer. Sovereign Labs describes this in detail in their design proposal called “Based Sequencing with Soft Confirmations,” which introduces the concept of “preferred sequencer.”
Since the MEV problem depends on the aggregator scheme chosen by the Rollup and the Rollup fork selection rule, some schemes do not leak MEV to the DA layer, while others leak some or all of the MEV to the DA layer, but this is another topic.
In terms of liveness, this Rollup scheme has advantages over schemes that only allow the shared aggregator to submit transactions to the DA layer. If the shared aggregator experiences liveness failures, users can still submit transactions to the DA layer.
Finally, let’s talk about the minimum configuration of Rollup users in a trust-minimized environment:
At least run a DA layer light node + a shared aggregator light node + a Rollup full node.
At this point, it is still necessary to verify the aggregator header published by the shared aggregator, so that the Rollup full node can distinguish transaction batches according to the fork selection rule.
Variant 4: Optimistic Based Rollup with Centralized Header Generator

Let’s discuss a variant called Based Optimistic Rollup with a centralized Header Generator. This scheme uses a DA layer to aggregate Rollup transactions, but introduces a centralized Header Generator to generate the Rollup Header, enabling Rollup light nodes.
Rollup light nodes can indirectly check the validity of Rollup transactions through single-round fraud proofs. Light nodes take an optimistic view of the Header Generator and provide final confirmation after the fraud proof window ends. Another possibility is that it receives fraud proofs from honest full nodes, indicating that the Header Generator has submitted incorrect data.
I don’t intend to explain in detail how single-round fraud proofs work in this article, as it goes beyond the scope of this article. The benefit of single-round fraud proofs is that they can reduce the fraud proof window from 7 days to a certain extent, with the specific value yet to be determined, but on a smaller scale than traditional optimistic rollups. Light nodes can obtain fraud proofs from a P2P network composed of Rollup full nodes, without waiting for subsequent dispute processes, as all evidence is provided in a single fraud proof.

In the above Rollup model, the DA layer serves as the aggregator and inherits its censorship resistance. The DA layer is responsible for including and ordering transactions. The centralized Header Generator reads the Rollup transaction sequence from the DA layer and constructs the corresponding Rollup Header based on it. The Header Generator publishes the Header and Stateroot to the DA layer. These Stateroots are required when creating fraud proofs. In short, the aggregator is responsible for including and ordering transactions, and the Header Generator performs transaction updates to obtain the Stateroot.
Suppose the DA layer (which also acts as the Rollup aggregator at this time) is sufficiently decentralized and has good censorship resistance. In addition, the Header Generator cannot change the Rollup transaction sequence published by the aggregator. Now, if the Header Generator is decentralized, the only benefit it brings is better liveliness, but the other properties of Rollup are the same as the first variant, Based Rollup.
If the Header Generator experiences liveliness failures, the Rollup will also experience liveliness failures. Light nodes will not be able to keep up with the progress of the Rollup ledger, but full nodes can. In this case, the Rollup described in Variant 4 degenerates into the Based Rollup described in Variant 1. Clearly, the minimal trust configuration described in Variant 4 is:
DA layer light nodes + Rollup light nodes.
Variant 5: Based ZK-Rollup with Decentralized Prover Market

We have discussed pessimistic Rollup (Based Rollup) and optimistic Rollup, and now it’s time to consider ZK-Rollup. Recently, Toghrul gave a speech on the separation of the Sequencer and Prover in this model (Sequencer-Prover Separation in Zero-Knowledge Rollups). In this model, it is easier to handle transactions as Rollup data rather than State Diffs, so I will focus on discussing the former. Variant 5 is a decentralized Prover Market based on zk-rollup.
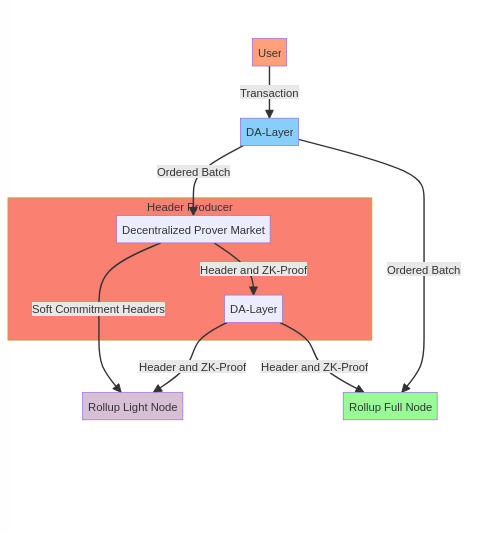
By now, you should have a good understanding of how Rollup works. Variant 5 delegates the aggregator role to the DA layer nodes, which handle the inclusion and ordering of transactions. I will quote the document from Sovereign-Labs, which provides a good explanation of the lifecycle of a transaction in Variant 5:
A user publishes a new data block to the L1 chain (DA layer). Once these data blocks are finalized on the L1 chain, they are logically considered to be final (immutable). Once the blocks on the L1 chain enter the finalization stage (i.e., cannot be rolled back), the Rollup full nodes scan these blocks, process all Rollup-related data blocks in order, and generate the latest Rollup state root, Stateroot. At this point, from the perspective of the Rollup full nodes, these data blocks have been finalized.
In this model, the Header generator is replaced by a decentralized Prover Market.
The workflow of the Prover Verifier nodes (full nodes running in ZKVM) is similar to that of regular Rollup full nodes – scan the DA layer blockchain and process all Rollup transaction batches in order – generate the corresponding zero-knowledge proof and publish it to the DA layer chain. (If the Rollup system wants to incentivize Prover Verifiers, they need to have the latter publish the generated ZK proofs to the DA layer chain; otherwise, it cannot be determined which Prover submitted the ZK proof first). Once the ZK proof corresponding to a transaction batch is published on the chain, that transaction batch is considered finalized by all Rollup nodes (including light nodes).
Variant 5 has the same resistance to censorship as the DA layer. The decentralized Prover Market cannot censor Rollup transactions because the transaction order has already been determined on the DA layer. It is only decentralized for better liveliness and to create an incentive market, so the Header generator (Prover) is decentralized.
The liveness here is L = L_da && L_pm (Prover’s liveness). If there is inconsistency in the Prover Market incentives or if there is a liveness failure, the Rollup light nodes will not be able to synchronize the blockchain progress, but the Rollup full nodes can. For the full nodes, this simply reverts back to what Variant 1 calls Based Rollup/Pessimistic Rollup. The minimum trust minimized configuration here is the same as in the case of Optimistic Rollup, which is
DA layer light nodes + Rollup light nodes.
Variant 6: Hybrid Based Rollup + Centralized Optimistic Header Generator + Decentralized Prover

We still have the DA layer nodes act as the aggregator for Rollup and delegate the inclusion and ordering of transactions to them.
As you can see from the diagram below, both ZK Rollup and Optimistic Rollup use the same ordered transaction batches on the DA layer as the source of the Rollup ledger. This is why we can use both proof systems simultaneously: the ordered transaction batches on the DA layer are not affected by the proof systems.

Let’s first talk about finality. From the perspective of a Rollup full node, when the blocks of the DA layer are finally confirmed, the batch of Rollup transactions included in it is also finally determined and cannot be changed. But we are more concerned about finality from the perspective of a light node. Assuming that the centralized Header producer mortgages some assets and signs on the generated Rollup Header, submitting the calculated Stateroot to the DA layer.
Similar to variant 4 mentioned earlier, the light node optimistically trusts the Header producer, believing that the Header it publishes is correct, and waits for fraud proofs from the full node network. If the window period for fraud proofs ends and no fraud proof is published by the full node network, from the perspective of the Rollup light node, the Rollup block is considered finally confirmed.
The key is that if we can obtain a ZK proof, we don’t have to wait for the end of the fraud proof window period. In addition to single-round fraud proofs, we can replace fraud proofs with ZK proofs and discard incorrect Headers generated by malicious Header producers!
When a light node receives a ZK proof corresponding to a certain batch of Rollup transactions, that batch is considered finally confirmed.
Now we have fast Soft Commitment and fast finality.
Variant 6 still has the same censorship resistance as the DA layer, as it is based on the DA layer. For liveness, we will have L = L_da && (L_op || L_pm), which means we increase the guarantee of liveness. If either the centralized Header producer or the decentralized Prover Market has a liveness failure, we can degrade to the other solution.
The minimal configuration for minimal trust in this variant is:
One DA layer light node + one Rollup light node.

Summary:
1. We split the key role of the Rollup sequencer, the Sequencer, into two logical components: the Aggregator and the Header producer.
2. We divide the work of the Sequencer into three logical processes: inclusion, sorting, and execution.
3. Pessimistic rollup and based rollup are the same thing.
4. Depending on the requirements, you can choose different Aggregator and Header producer schemes.
5. Each Rollup variant described in this article follows the same design pattern:

Finally, I have some thoughts for you to consider:
- How does the classic Rollup (referring to Ethereum Rollup) fit into the above variants?
- In all variants, we only let the Aggregator be responsible for inclusion + sorting, and the Header producer executes the transactions. What if the Aggregator is only responsible for inclusion and the Header producer is responsible for sorting and executing transactions? Considering the introduction of on-chain auction steps, can we completely separate these three steps of work?
- What is the shared Header Producer/Header Producer Market?
- Who captures the MEV value? Can users retrieve it?
Like what you're reading? Subscribe to our top stories.
We will continue to update Gambling Chain; if you have any questions or suggestions, please contact us!
