
Editor’s note: This article is mainly based on David Aronchick’s speech at the Filecoin Unleashed conference in Paris in 2023. David is the CEO of ExLianGuainso and the former head of data computing at Protocol Labs, which is responsible for launching the Bacalhau project. This article represents the independent views of the original content creator and has been granted permission for republishing.
According to IDC, the global amount of stored data is expected to exceed 175 ZB by 2025. This is a massive amount of data, equivalent to 175 trillion 1 GB USB drives. Most of this data will be generated between 2020 and 2025, with a projected compound annual growth rate of 61%.
Today, the fast-growing data sphere faces two major challenges:
- Revealing how Musk acquired Twitter His decision-making process and insider information
- Football superstar Ronaldinho denies involvement in $61 million cryptocurrency scam
- A Summary of the Potential of TG Bots Who Will Be the Next Unibot?
-
Slow and expensive data mobility. If you try to download 175 ZB of data with current bandwidth, it would take approximately 1.8 billion years.
-
Heavy compliance tasks. There are hundreds of data-related management regulations globally, making cross-jurisdictional compliance tasks nearly impossible to complete.
The combined result of sluggish network growth and regulatory limitations is that nearly 68% of institutional data remains idle. Therefore, it becomes increasingly important to transfer computational resources to where the data is stored (broadly known as compute-over-data or “data computing”) instead of moving the data to where the computation happens. Platforms like Bacalhau are striving to achieve this.
In the following sections, we will briefly introduce:
-
How institutions currently handle data.
-
Alternative solutions based on “data computing”.
-
Finally, why distributed computing is important.
Current Situation
Currently, institutions mainly adopt the following three approaches to address data processing challenges, but none of them are ideal.
Using centralized systems
The most common approach is to use centralized systems for large-scale data processing. We often see institutions combining computing frameworks such as Adobe Spark, Hadoop, Databricks, Kubernetes, Kafka, and Ray to form a cluster system network connected to a centralized API server. However, these systems fail to effectively address network congestion issues and other regulatory problems related to data mobility.
This has led to institutions being fined billions of dollars and facing penalties due to data breaches.
Self-building
Another approach is to have developers build custom coordination systems that meet the institution’s requirements for visibility and robustness. While this approach is novel, it often carries the risk of failure due to over-reliance on a few individuals to maintain and operate the system.
Doing nothing
Surprisingly, in most cases, institutions do nothing with their data. For example, a city may collect a large amount of data from surveillance videos every day, but due to high costs, this data is only used for viewing on local machines and cannot be archived or processed.
Building True Distributed Computing
There are two main solutions to the pain points of data processing.
Solution 1: Built on top of open-source data computing platforms

Solution 1: Open-source data computing platform
Developers can use open-source distributed data platforms for computing instead of custom coordination systems mentioned earlier. Because this platform is open-source and scalable, organizations only need to build the necessary components. This setup can meet the requirements of multi-cloud, multi-computing, and non-data center applications, and can handle complex regulatory environments. Importantly, access to the open-source community is no longer dependent on one or more developers for system maintenance, reducing the likelihood of failures.
Solution 2: Built on top of distributed data protocols
With the help of advanced computing projects like Bacalhau and LilyLianGuaid, developers can go further and build systems not only on the open-source data platform mentioned in Solution 1 but also on truly distributed data protocols like the Filecoin network.
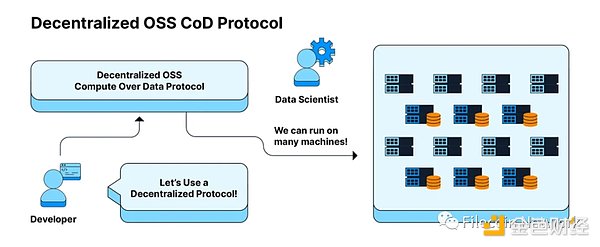
Solution 2: Distributed data computing protocol
This means organizations can use distributed protocols that know how to coordinate and describe user problems in a more granular way, unlocking computational areas close to where data is generated and stored. This transformation from data centers to distributed protocols can ideally be done with minimal changes to the experience of data scientists.
Distributed Means Maximizing Choice
By deploying on distributed protocols like the Filecoin network, our vision is that users can access hundreds (or thousands) of machines distributed in different regions on the same network and follow the same protocol rules as other machines. This essentially opens up a sea of choices for data scientists, as they can request the network to:
-
Access datasets from anywhere in the world.
-
Follow any governance structure, whether it’s HILianGuaiA, GDPR, or FISMA.
-
Run at the lowest possible cost.
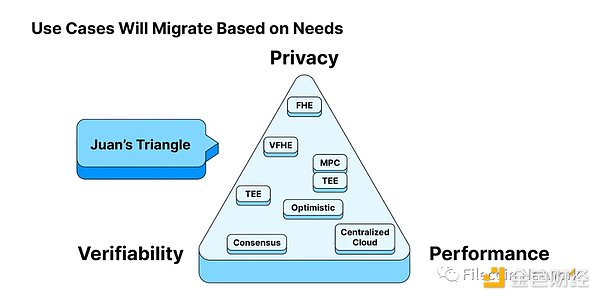
Juan’s Triangle | Decoding Acronyms: FHE (Fully Homomorphic Encryption), MPC (Multi-Party Computation), TEE (Trusted Execution Environment), ZKP (Zero-Knowledge Proof)
When it comes to the concept of maximizing choice, we have to mention “Juan’s Triangle,” a term coined by Juan Benet, the founder of Protocol Labs, to explain why different use cases will have different distributed computing networks to support them in the future.
Juan’s Triangle proposes that computing networks typically need to balance privacy, verifiability, and performance, and a traditional “one-size-fits-all” approach is difficult to apply to every use case. Instead, the modular nature of distributed protocols allows different distributed networks (or sub-networks) to meet different user needs, whether it’s privacy, verifiability, or performance. Ultimately, we will optimize based on factors we deem important. At that time, there will be many service providers (as shown in the boxes within the triangle) filling these gaps and making distributed computing a reality.
In conclusion, data processing is a complex issue that requires ready-to-use solutions. Using open-source data computing as an alternative to traditional centralized systems is a good first step. Ultimately, deploying a computing platform on distributed protocols like the Filecoin network allows for the free configuration of computing resources based on users’ personalized needs, which is crucial in the era of big data and artificial intelligence.
Like what you're reading? Subscribe to our top stories.
We will continue to update Gambling Chain; if you have any questions or suggestions, please contact us!
