Since Satoshi Nakamoto decided to embed a message in the genesis block, the data structure of the Bitcoin chain has undergone a series of changes.
I started studying blockchain development in 2022, and the first book I read was “Mastering Ethereum”. This book is excellent and provides me with a deep understanding of Ethereum and blockchain basics. However, from the current perspective, some of the development techniques in the book are somewhat outdated. The initial steps involve running a node on a personal laptop, even for wallet dApps, which requires downloading a light node. This reflects the behavior patterns of early developers and hackers in the blockchain development ecosystem from 2015 to 2018.
Looking back to 2017, we didn’t have any node service providers. From the perspective of supply and demand, due to limited user activity, their main function was to conduct transactions. This means that maintaining or hosting a full node on your own does not impose a heavy burden because there aren’t many RPC requests to handle, and transfer requests are not frequent. Most early adopters of Ethereum were technical geeks. These early users had a deep understanding of blockchain development and were accustomed to maintaining Ethereum nodes, creating transactions, and managing accounts directly through the command line or integrated development environment.
Therefore, we can observe that early projects usually had very simple user interfaces/user experiences. Some of these projects didn’t even have a frontend, and user activity was quite low. The characteristics of these projects were mainly determined by two factors: user behavior and the data structure of the chain.
- What is Spyware? How dangerous is Spyware in cryptocurrencies?
- In conversation with the founder of Nil Foundation ZK technology may be misused, public traceability is not the original intention of encryption.
- What are the advantages of Layer1’s newcomer Sei Network in terms of technical mechanisms?
The Rise of Node Providers
As more and more non-programming background users enter the blockchain network, the technical architecture of decentralized applications has also changed. The pattern of user-hosted nodes has gradually shifted to node hosting by project parties.
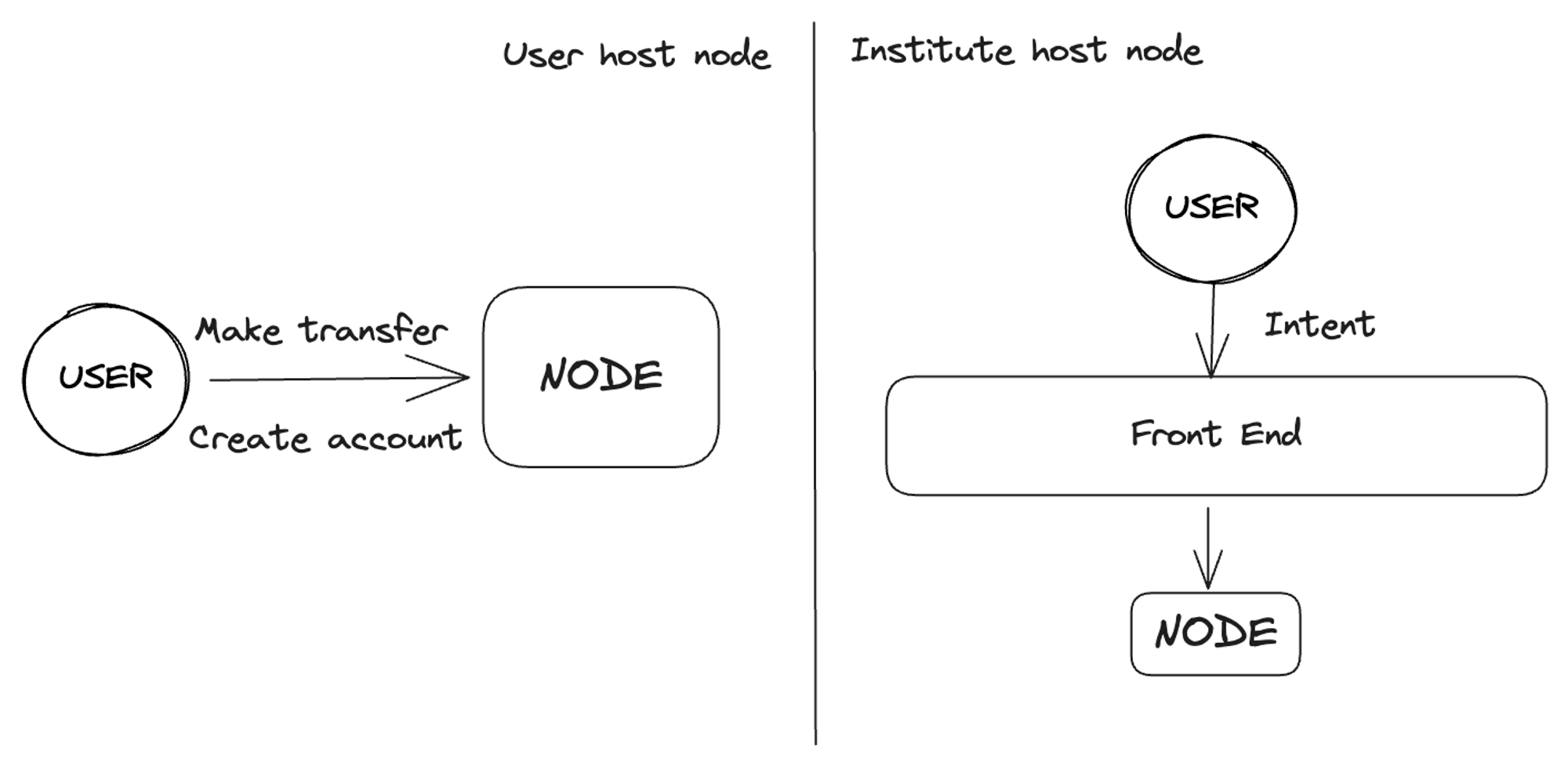
People tend to choose node hosting services mainly because the rapid growth of on-chain data has led to increasing costs for individual hosted nodes over time.
However, for developers of small projects, self-hosting nodes is still a challenge as it requires continuous maintenance and hardware costs. Therefore, this complex node hosting process is often entrusted to companies specializing in node maintenance. It is worth mentioning that the timing of these companies’ large-scale construction and fundraising coincides with the rise of cloud services in the North American tech industry.
| Project | Category | Established since |
|---|---|---|
| Alchemy | Nodes | 2017 |
| Infura | Nodes | 2016 |
| NowNodes | Nodes | 2019 |
| QuickNodes | Nodes | 2017 |
| Ankr | Nodes | 2017 |
| ChainStack | Nodes | 2018 |
Just hosting remote nodes alone cannot completely solve the problem, especially now with the rise of protocols such as DeFi and NFT. Developers need to deal with a large amount of data because the data provided by blockchain nodes themselves is called raw data, which is not standardized and cleaned. The data needs to be extracted, cleaned, and loaded.
For example, let’s say I’m a developer of an NFT project and I want to trade or display NFTs. Then my front end needs to read the NFT data from my personal EOA account in real time. NFTs are actually just a standardized form of tokens. Owning an NFT means that I own a token with a unique ID generated by the NFT contract, and the image of the NFT is actually metadata, which could be SVG data or a link to an image on IPFS. Although Ethereum’s Geth client provides indexing instructions, it is not practical for some front-end heavy projects to continuously request Geth and return the results to the front end. For some functions, such as order auctions and NFT trading aggregators, they must be done off-chain to collect user instructions and then submit these instructions to the chain at the right time.
Therefore, a simple data layer is needed. In order to meet the requirements of real-time and accuracy for users, project teams need to build their own databases and data parsing functions.
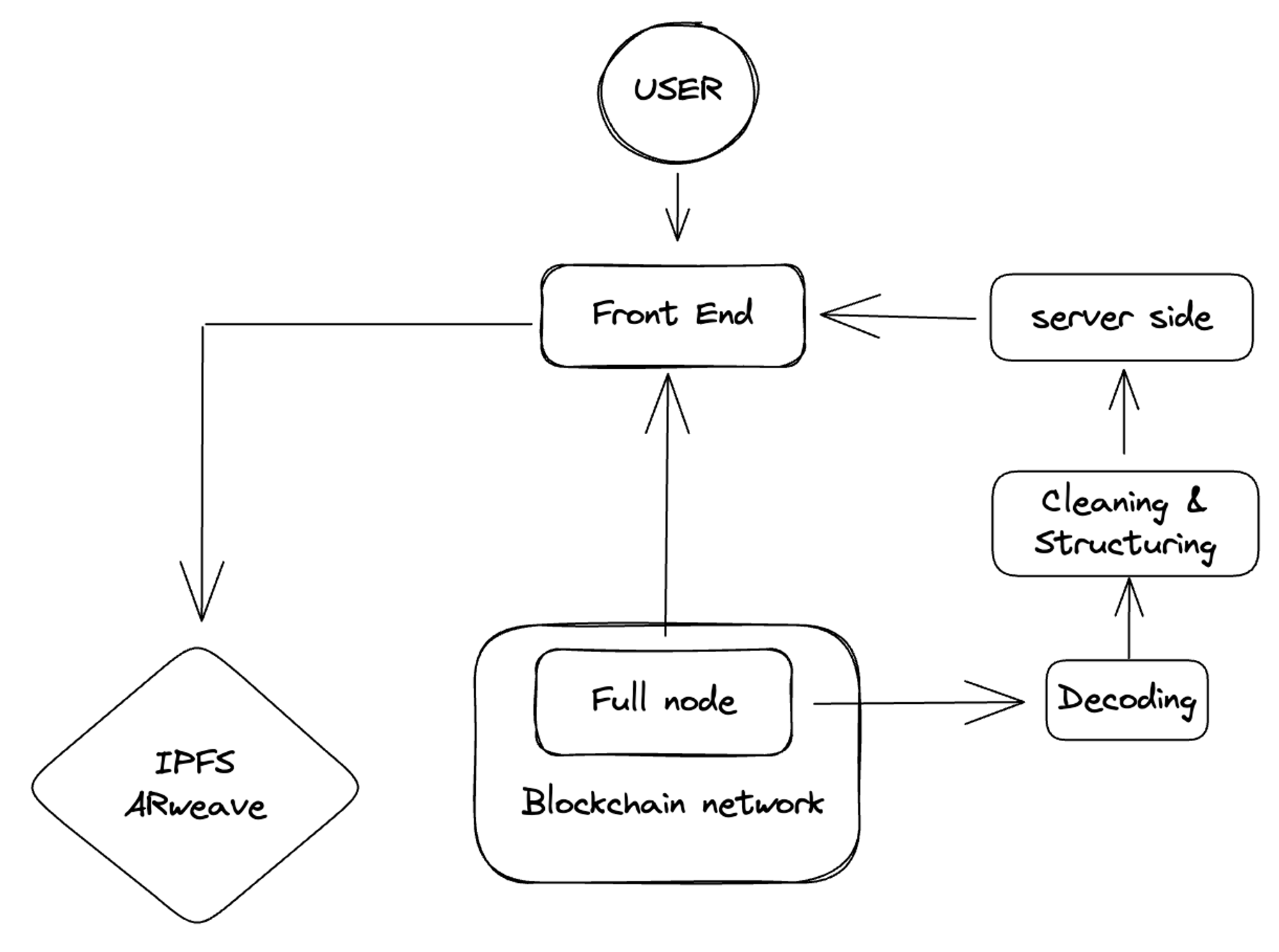
How has data indexer evolved?
Launching a project is usually a relatively simple task. You have an idea, set some goals, find the best engineers, and build a practical prototype, which usually includes front-end and several smart contracts.
However, scaling the project is quite difficult. People need to think carefully about the design structure from the first day of the project. Otherwise, you will soon encounter some problems, which I often refer to as “freezing problems”.

I borrowed this term from the movie “Iron Man”, and it seems to be very suitable for describing the situation of most startups. When a startup grows rapidly (attracts a large number of users), they often encounter difficulties because they did not anticipate this situation in the beginning. In the movie, the villain did not anticipate his war equipment flying into space because he did not consider the “freezing problem”. Similarly, for many Web3 project developers, the “freezing problem” involves dealing with the increased burden brought by the adoption of a large number of users. As the number of users grows rapidly, this puts a heavy burden on the server side. There are also some problems related to the blockchain itself, such as network issues or node shutdowns.
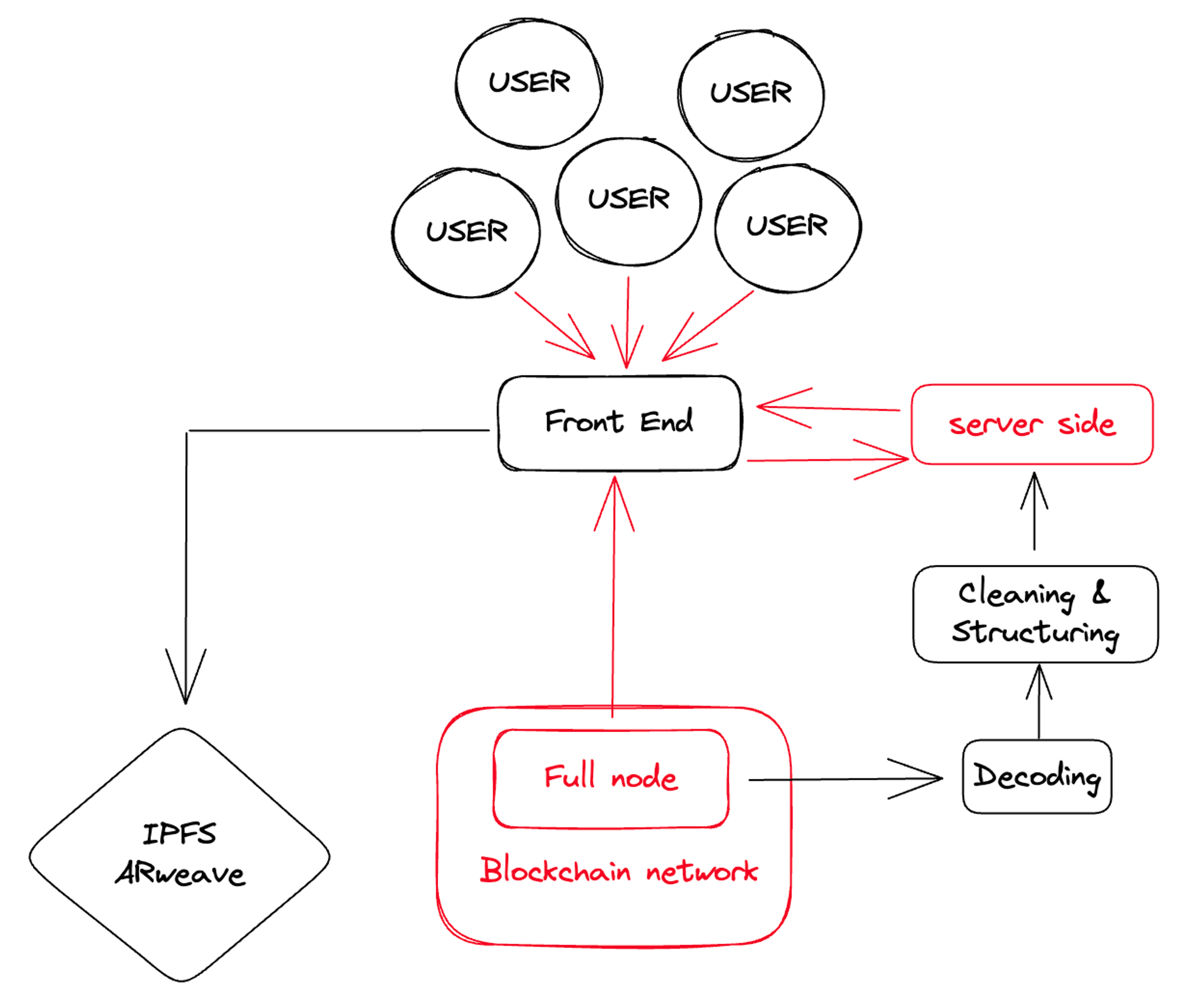
In most cases, this is a backend problem. For example, this is quite common in some blockchain gaming protocols. When they plan to add more servers and hire more data engineers to parse on-chain data, they did not anticipate that so many users would participate. By the time they realize this, it’s already too late. And these technical problems cannot be solved simply by adding more backend engineers. As I mentioned earlier, these considerations should be included in the plan from the beginning.
The second issue involves adding a new blockchain. You may have initially avoided the server-side issues and hired a team of excellent engineers. However, your users may not be satisfied with the current blockchain. They want your service to also run on other popular chains, such as zk chains or L2 chains. Your project architecture may eventually look like this:
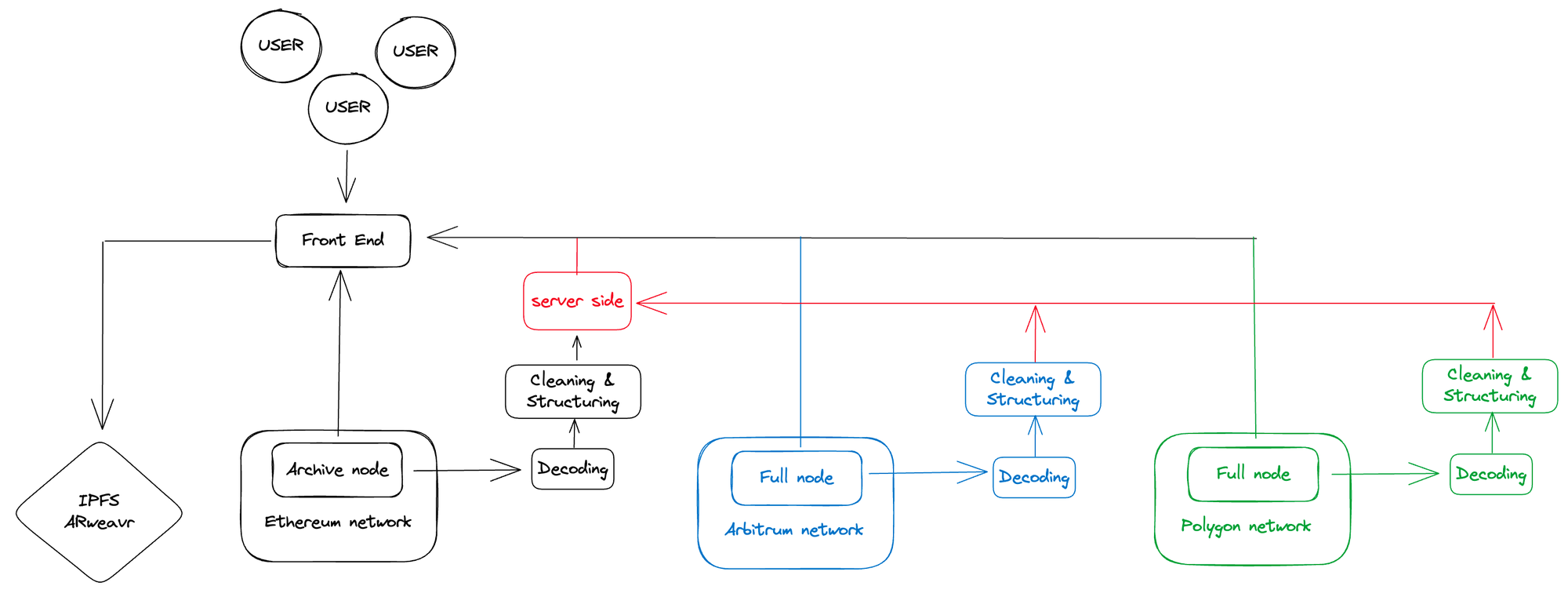
In this system, you have complete control over your own data, which helps with better management and improved security. The system limits call requests, reducing the risk of overload and improving efficiency. Furthermore, this setup is compatible with the frontend, ensuring seamless integration and user experience.
However, the operational and maintenance costs will increase exponentially, which may put pressure on your resources. Adding a new blockchain requires repetitive work, which can be time-consuming and inefficient. Selecting data from a large dataset may reduce query time but potentially slow down the process. Due to blockchain network issues, such as rollbacks and reorganizations, data may be contaminated, compromising data integrity and reliability.
The design of the project reflects your team members. Adding more nodes and trying to build a backend-heavy system means you need to hire more engineers to operate these nodes and decode raw data.
This pattern is similar to the early days of the internet, where e-commerce platforms and application developers chose to build their own IDC (Internet Data Center) facilities. However, as user requests grow and blockchain network status explodes, costs and the complexity of program design go hand in hand. Additionally, this approach hinders the rapid expansion of the market. Certain high-performance public blockchains require hardware-intensive node operations, while data synchronization and cleaning continuously consume human and time costs.
If you are trying to build a blockchain-based NFT marketplace or a cool game, isn’t it strange that 65% of your team members are backend and data engineers?
Perhaps developers would wonder why no one is helping them decode and transmit this on-chain data so that they can focus on building better products.
I believe this is why indexers exist.
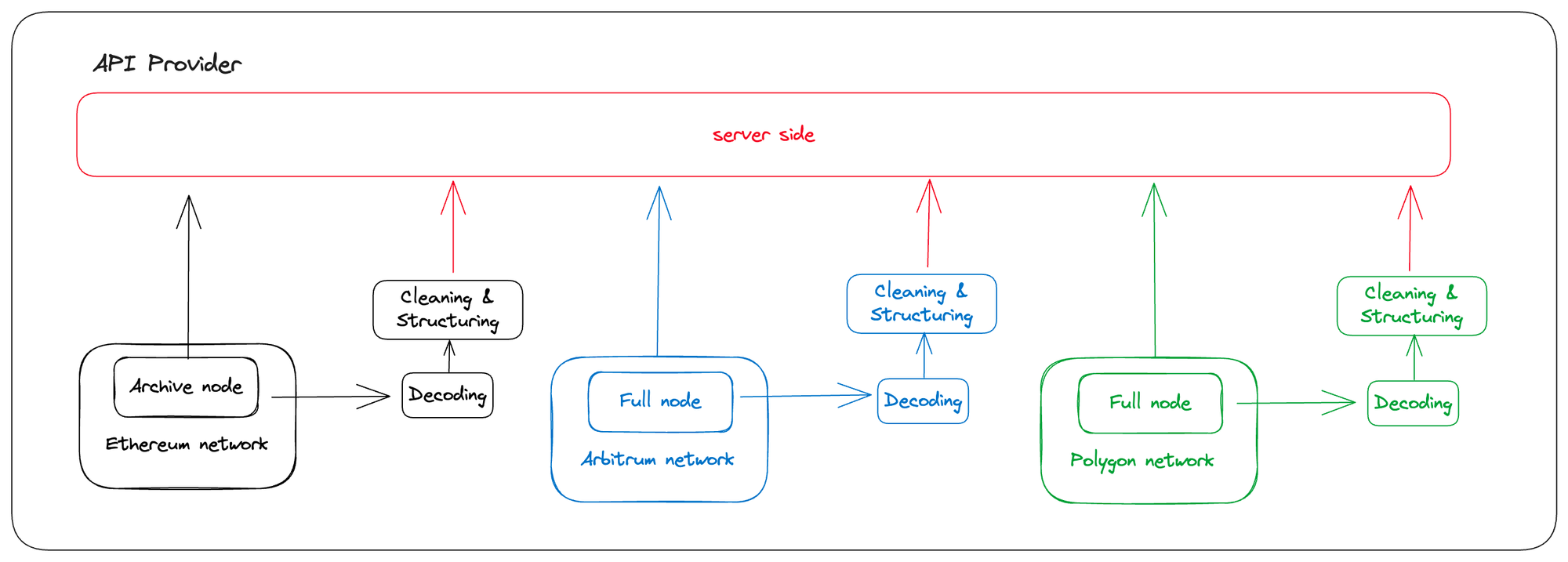
To lower the difficulty of accessing Web3 applications and blockchain networks, many development teams, including us, choose to integrate the maintenance of archival nodes, on-chain data ETL (Extract, Transform, Load), and database calls. These tasks originally required the project team to maintain them on their own, but now they are integrated by providing multi-chain data and node APIs.
With the help of these APIs, users can customize on-chain data according to their own needs. This includes various needs, such as popular NFT metadata, monitoring on-chain activities of specific addresses, and tracking transaction data of specific token liquidity pools. I often refer to this approach as part of the modern Web3 project structure.
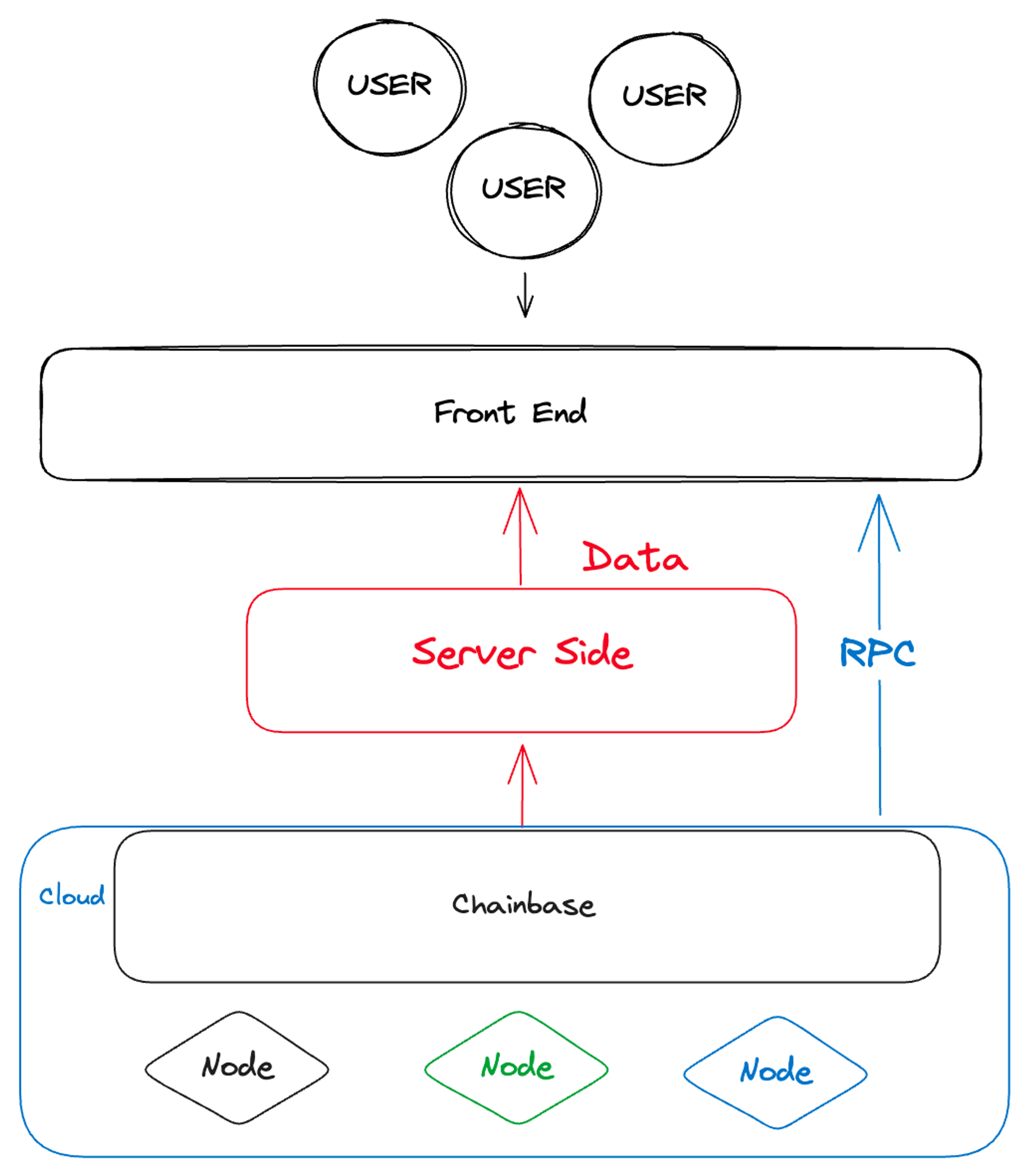
The financing and construction of the data layer and index layer projects will mainly take place in 2022. I believe that the commercial practices of these index layer and data layer projects are closely related to the design of their underlying data architecture, especially the design of OLAP (On-Line Analytical Processing) systems. Adopting the appropriate core engine is the key to optimizing the performance of the index layer, including improving the indexing speed and ensuring its stability. Commonly used engines include Hive, SLianGuairk SQL, Presto, Kylin, ImLianGuaila, Druid, ClickHouse, etc. Among them, ClickHouse is a powerful database widely used in internet companies. It was open-sourced in 2016 and received $250 million in financing in 2021.
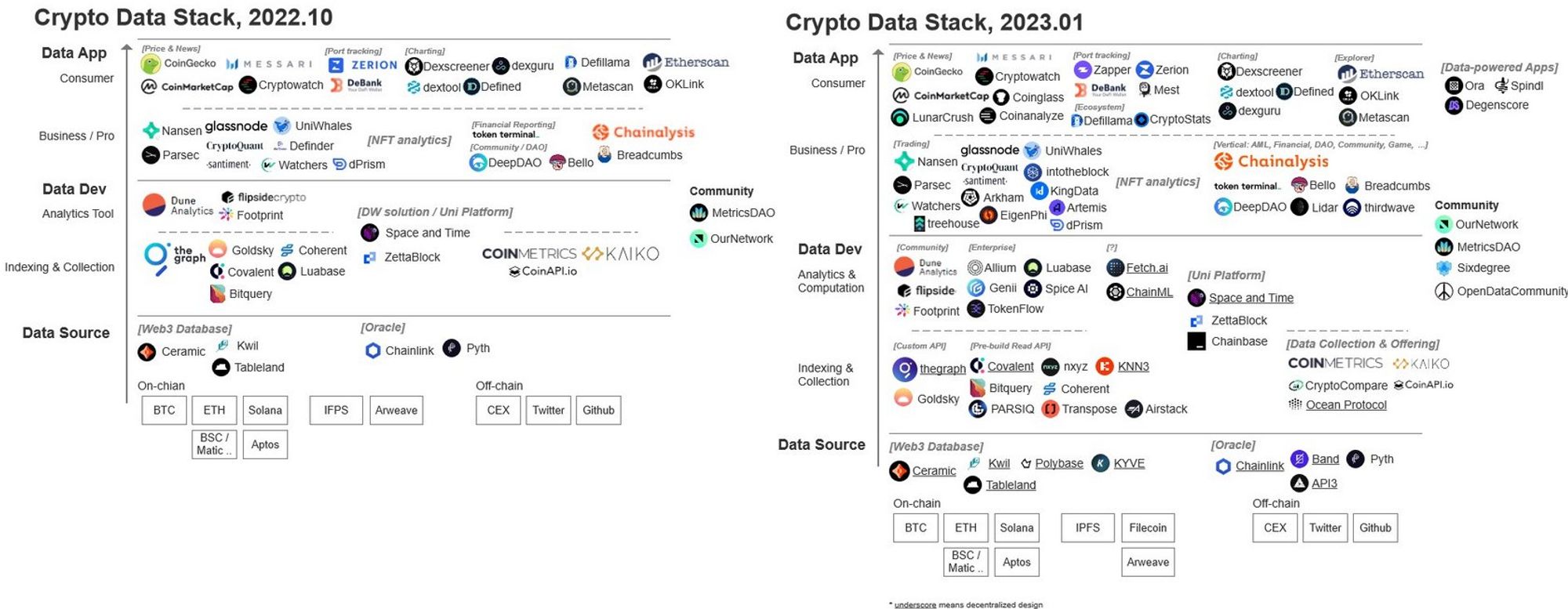
Therefore, the emergence of the new generation of databases and improved data index optimization architecture has led to the creation of the Web3 data index layer. This enables companies in this field to provide data API services in a faster and more efficient manner.
However, the building of on-chain data indexing is still overshadowed by two dark clouds.
Two Dark Clouds
The first dark cloud concerns the impact of blockchain network stability on server-side. Although the blockchain network has strong stability, it is not the case during data transmission and processing. For example, events such as blockchain reorganizations and rollbacks can pose challenges to the data stability of indexers.
Blockchain reorganization refers to the temporary loss of synchronization by nodes, resulting in the simultaneous existence of two different versions of the blockchain. Such situations can be caused by system failures, network delays, or even malicious behavior. When the nodes resynchronize, they will converge to a unique official chain, and the previously alternative “forked” blocks will be discarded.
During a reorganization, the indexer may have already processed data from the blocks that will eventually be discarded, resulting in database contamination. Therefore, the indexer must adapt to this situation, discard data from the invalid chain, and reprocess data from the newly accepted on-chain.
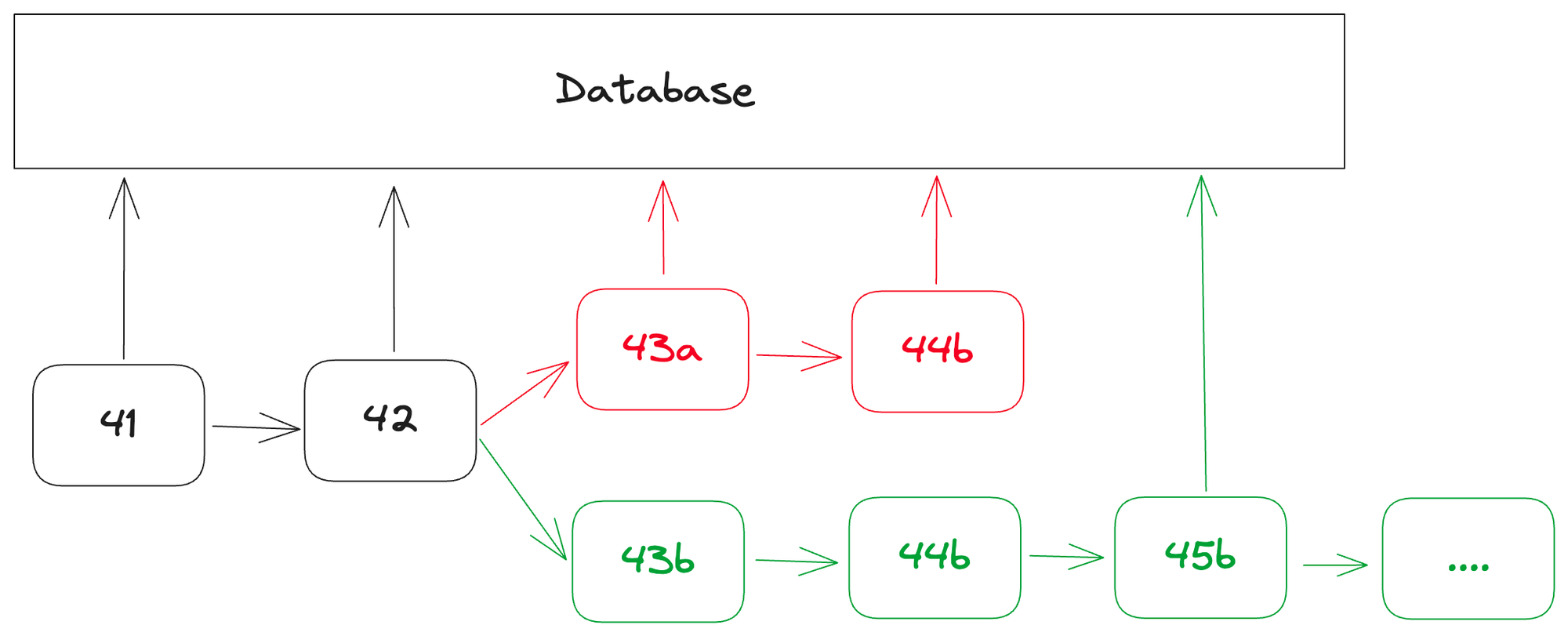
Such adjustments may increase resource usage and potentially delay data availability. In extreme cases, frequent or large-scale block reorganizations can seriously affect the reliability and performance of services that rely on indexers, including Web3 applications that use APIs to retrieve data.
In addition, we also face issues of data format compatibility and diversity of data standards among blockchain networks.
In the field of blockchain technology, there are numerous different networks, each with its own unique data standards. For example, there are EVM (Ethereum Virtual Machine) compatible chains, non-EVM chains, and zk (zero-knowledge) chains, each with its own special data structures and formats.
This is undoubtedly a big challenge for indexers. In order to provide useful and accurate data through APIs, indexers need to be able to handle these diverse data formats. However, due to the lack of universal standards for blockchain data, different indexers may use different API standards. This can lead to data compatibility issues, where data extracted and converted from one indexer may not be usable in another system.
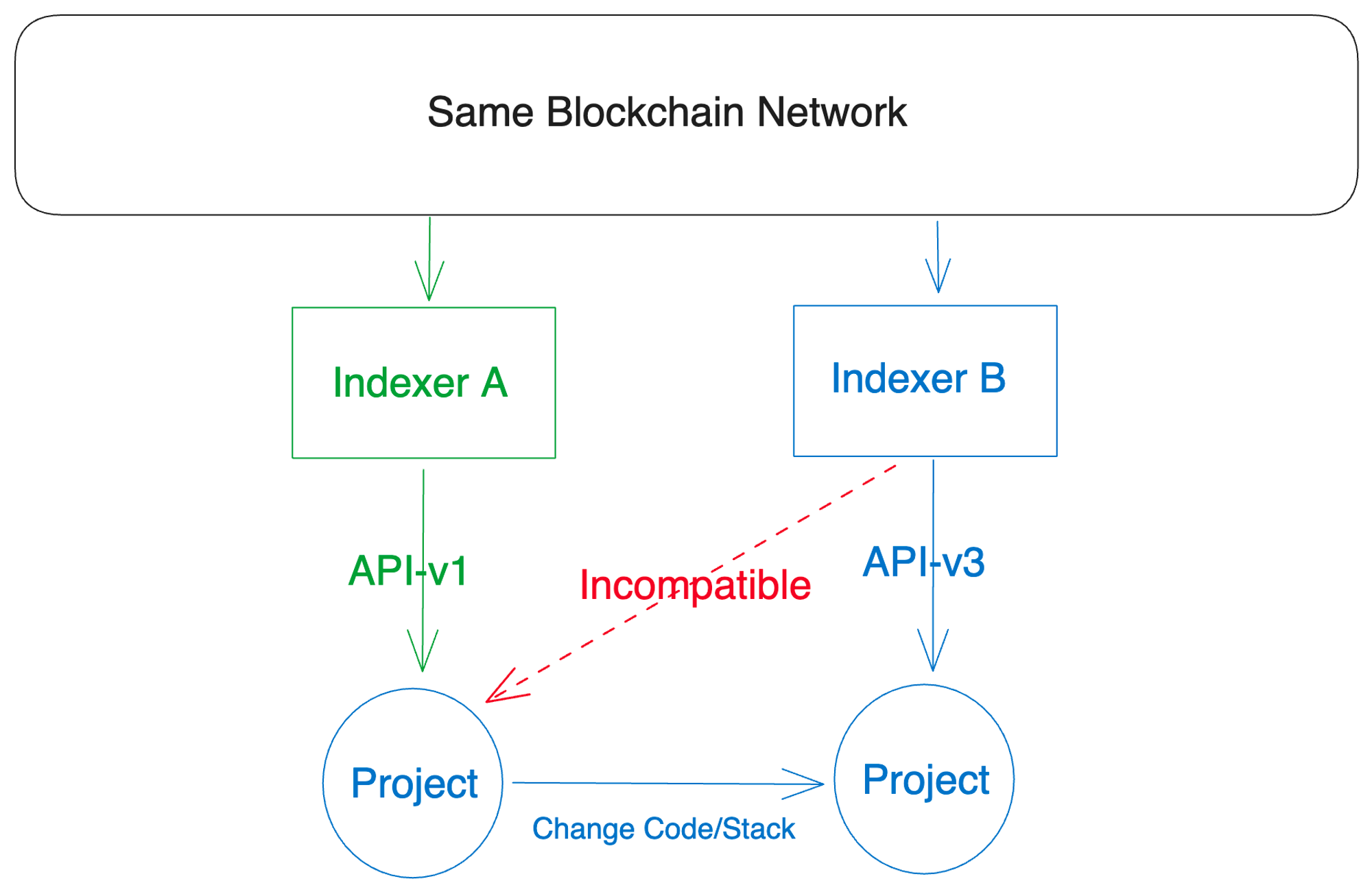
In addition, developers often face the challenge of dealing with these different data standards when exploring this multi-chain world. A solution that works for one blockchain network may not be effective for another, making it difficult for applications to interact with multiple networks.
Indeed, the challenges faced by the blockchain indexing industry evoke the two unresolved problems identified by Lord Kelvin in physics in the early 20th century, which ultimately gave rise to revolutionary fields such as quantum mechanics and thermodynamics.
In the face of these challenges, the industry has indeed taken some measures, such as introducing delays or integrating stream processing in Kafka pipelines, or even establishing a standard consortium to strengthen the blockchain indexing industry. These measures currently address the instability of blockchain networks and the diversity of data standards, enabling indexers to provide accurate and reliable data.
However, just as the emergence of quantum theory revolutionized our understanding of the physical world, we can also consider more radical approaches to improve blockchain data infrastructure.
After all, existing infrastructure, with its orderly data repositories and stacks, may appear too perfect, too beautiful to be true.
So, are there other paths to explore?
Finding Patterns
Let’s go back to the initial topic of node providers and indexers and consider a curious question. Why didn’t node operators appear in 2010, while indexers suddenly emerged in 2022 and received a large amount of investment?
I believe my previous text partially answered these questions. This is because cloud computing and data warehousing technologies have been widely used in the software industry, not just in the crypto field.
Something special has happened in the crypto field as well, especially when the ERC20 and ERC721 standards gained popularity in the public media. In addition, the DeFi summer made on-chain data more complex. Various function calls were routed on different smart contracts, not just simple transaction data as in the early stages, and the format and complexity of on-chain data have undergone astonishing changes and growth.
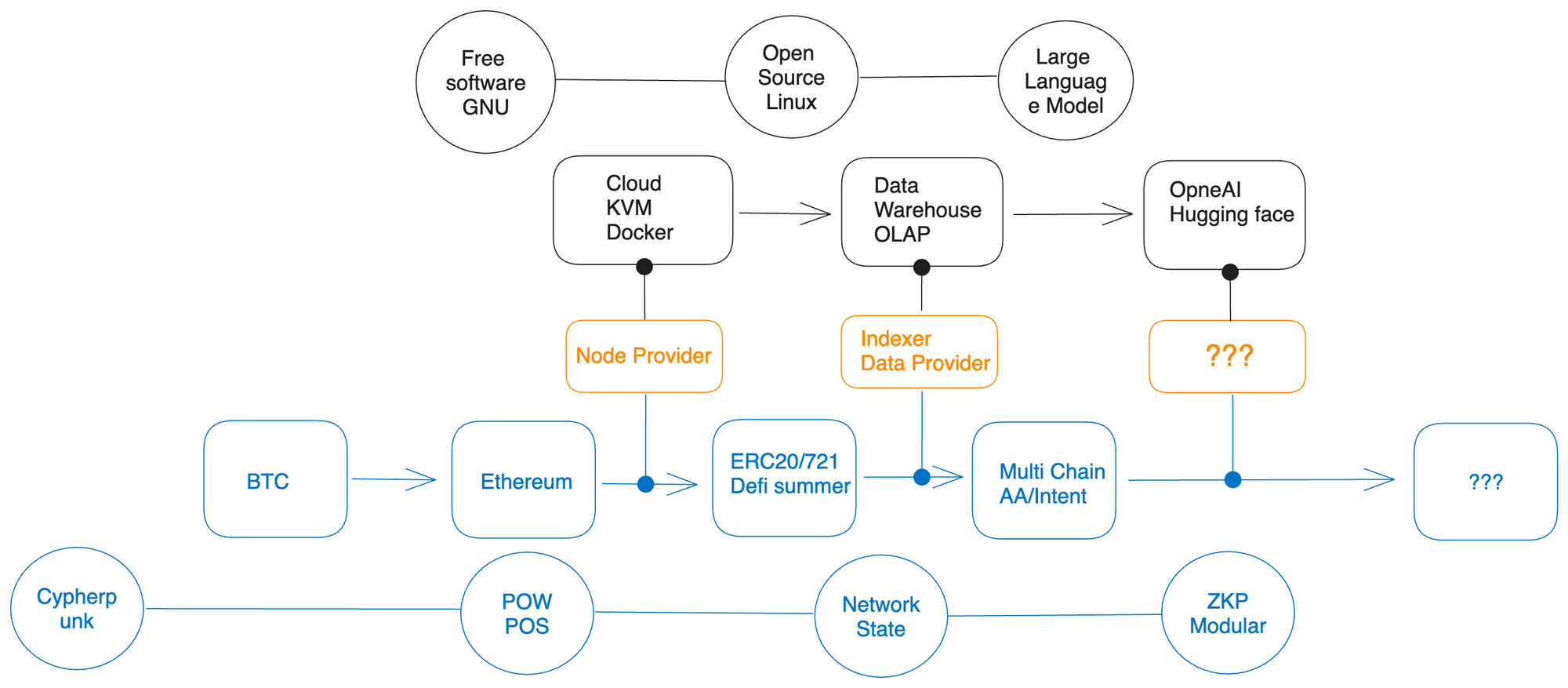
While there has been a strong emphasis within the cryptocurrency community on cutting ties with traditional Web2 technologies, we cannot overlook the fact that the development of cryptocurrency infrastructure relies on the continuous development and breakthroughs in fields such as mathematics, cryptography, cloud technology, and big data. Similar to the traditional Chinese mortise and tenon structure, the various components of the cryptocurrency ecosystem are closely interconnected.
The progress of technology and innovative applications are always subject to certain objective principles. For example, without the foundation of elliptic curve cryptography, our current cryptocurrency ecosystem would not exist. Similarly, without the important research paper on zero-knowledge proofs published by MIT in 1985, the practical application of zero-knowledge proofs would not have been achieved. Therefore, we can observe an interesting pattern. The widespread application and expansion of node service providers is based on the rapid growth of global cloud services and virtualization technology. At the same time, the development of the on-chain data layer is based on excellent open-source database architecture and flourishing services, which are the data solutions relied upon by numerous business intelligence products in recent years. These are the technological prerequisites that startup companies must meet in order to achieve commercial viability. For Web3 projects, those that adopt advanced infrastructure often have advantages over projects that rely on outdated architectures. The erosion of OpenSea’s market share by faster and more user-friendly NFT exchanges is a vivid example.
In addition, we can also see a clear trend: artificial intelligence (AI) and LLM technology have gradually matured and have the potential for extensive application.
Therefore, an important question arises: how will AI change the landscape of on-chain data?
Predicting the Future
Predicting the future is always challenging, but we can explore possible answers by understanding the problems encountered in blockchain development. Developers have a clear demand for on-chain data: they need on-chain data that is accurate, timely, and easy to understand.
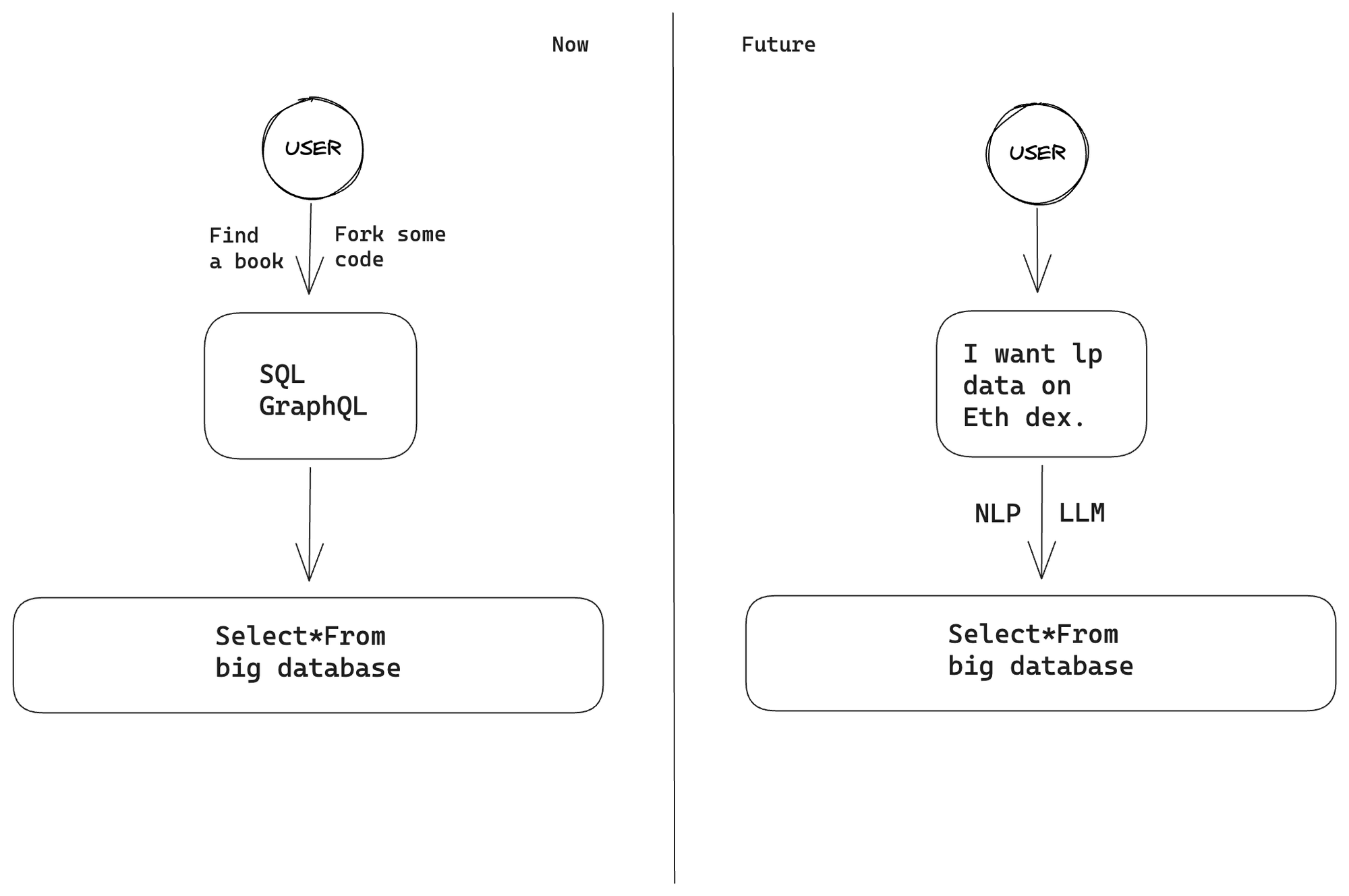
One problem we currently face is that batch retrieval or display of certain data requires complex SQL queries. This is why Dune’s open-source SQL functionality is so popular in the crypto community. Users don’t need to start from scratch to write SQL to build charts; they can simply fork and modify the smart contract addresses they want to focus on to create the charts they need. However, this is still too complex for ordinary users who only want to view liquidity or airdrop data under specific conditions.
I believe that the first step in solving this problem is to leverage LLM and natural language processing.
We can build a more user-centered “data query” interface and use LLM technology. In the current situation, users have to use complex query languages such as SQL or GraphQL to extract the corresponding on-chain data from APIs or Studios. However, by using LLM, we can introduce a more intuitive and human-friendly way of asking questions. In this way, users can express their questions in “natural language,” and then LLM will convert them into appropriate queries and provide users with the answers they need.
From a developer’s perspective, artificial intelligence can also optimize the parsing of on-chain contract events and ABI decoding. Currently, many details of DeFi contracts require developers to manually parse and decode. However, with the introduction of artificial intelligence, we can significantly improve various contract disassembly techniques and quickly retrieve the corresponding ABI. Combined with large language models (LLM), this configuration can intelligently parse function signatures and efficiently handle various data types. Furthermore, when this system is combined with “stream computing” processing frameworks, it can handle the real-time parsing of transaction data to meet users’ immediate needs.
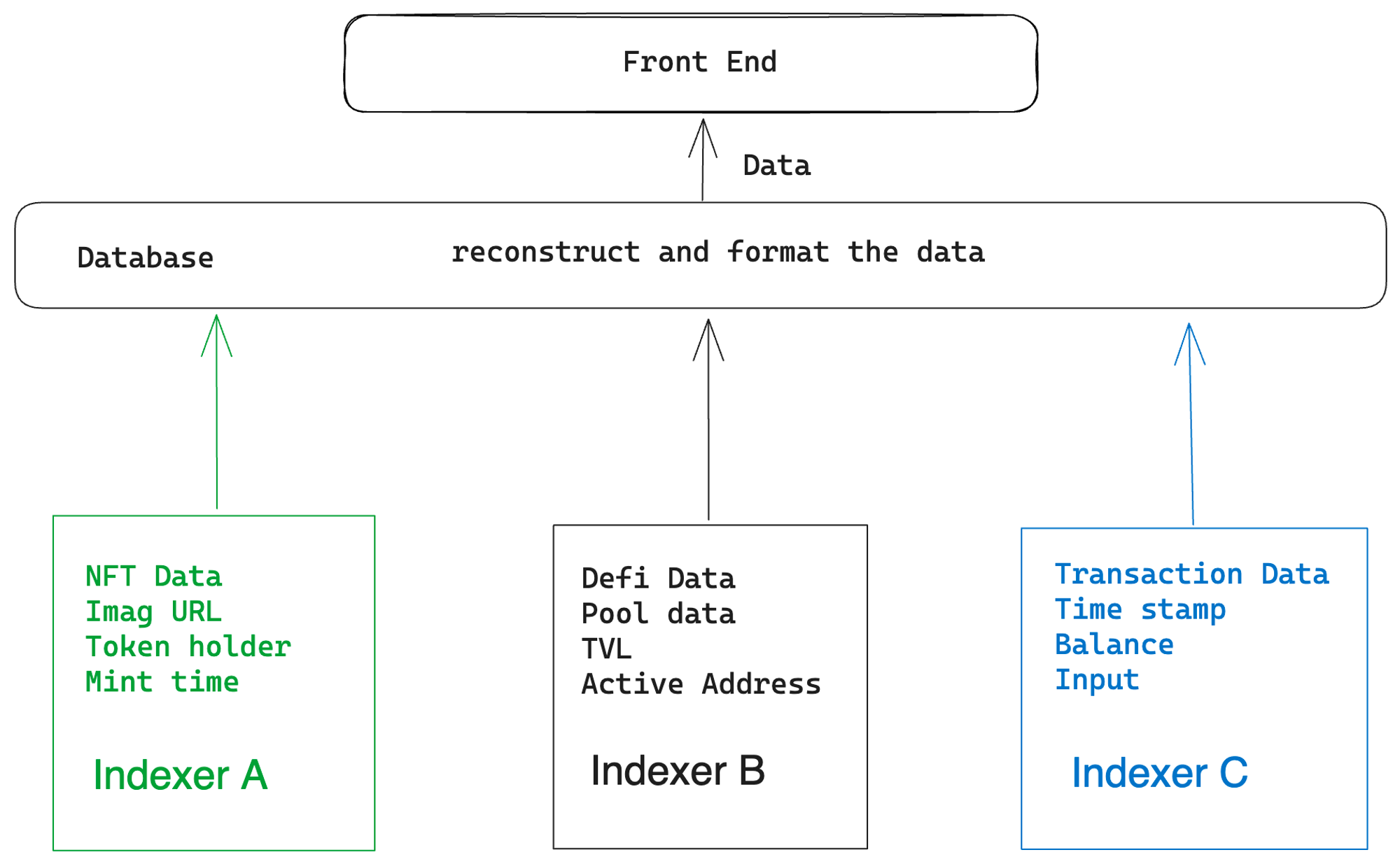
From a more global perspective, the goal of the indexer is to provide users with accurate data. As I mentioned before, a potential problem with the on-chain data layer is that the various data fragments are scattered across different indexer databases and isolated from each other. In order to meet diverse data needs, some designers choose to integrate all on-chain data into a single database, allowing users to select the desired information from a single dataset. Some protocols choose to include only certain data, such as DeFi data and NFT data. However, the problem of incompatible data standards still exists. Sometimes, developers need to retrieve data from multiple sources and reformat it in their own database, which undoubtedly increases their maintenance burden. In addition, once a data provider encounters problems, they cannot migrate to another provider in a timely manner.
So, how does LLM and artificial intelligence solve this problem? LlamaIndex provides me with an insight. What if developers don’t need an indexer and instead use a deployed proxy service (agent) to directly read the original on-chain data? What would happen then? This agent combines the technologies of the indexer and LLM. From the user’s perspective, they don’t need to know anything about APIs or query languages, they just need to ask questions and get instant feedback.
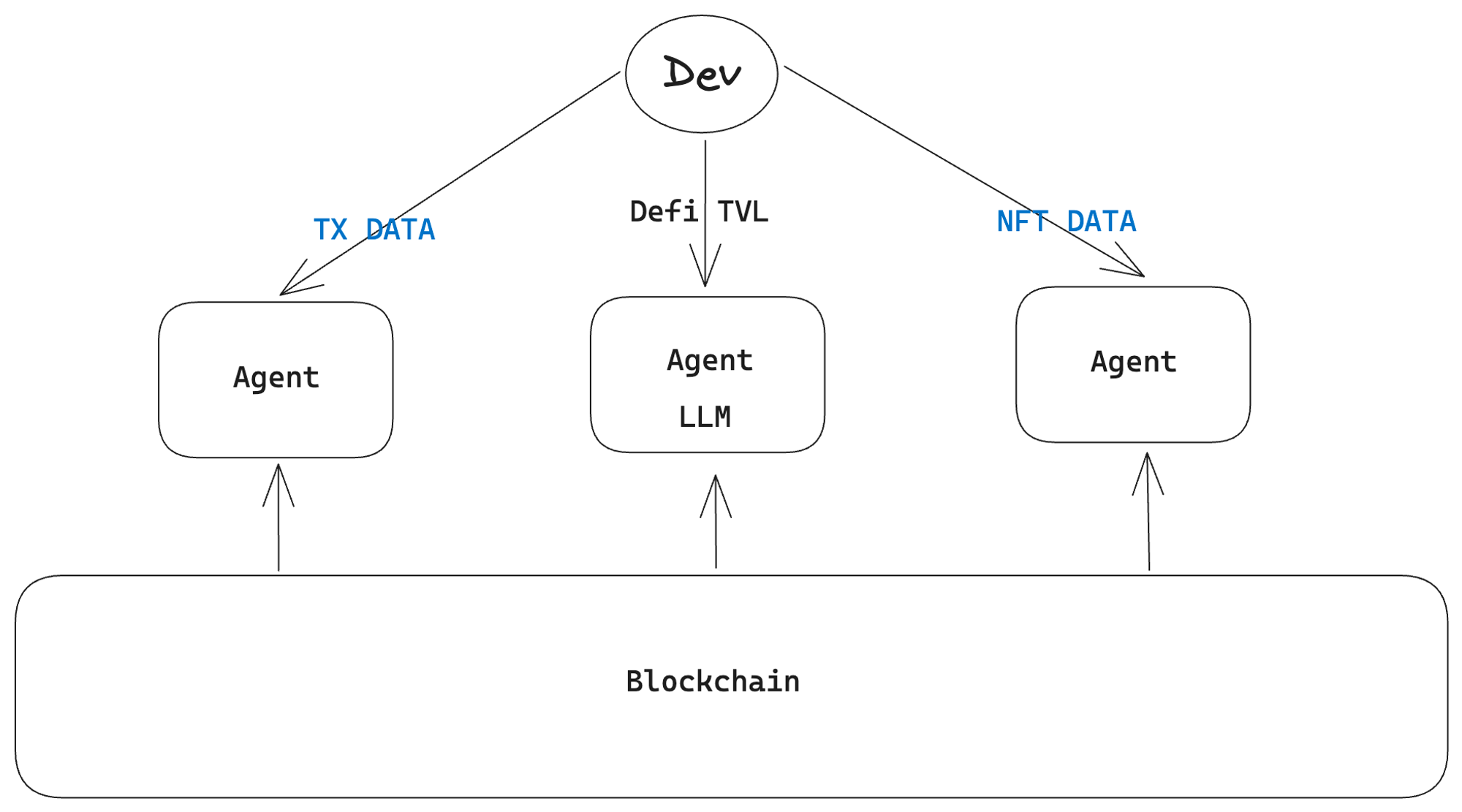
Equipped with LLM and artificial intelligence technology, the agent can understand and process the raw data and convert it into a format that is easy for users to understand. This eliminates the user’s frustration with complex APIs or query languages, and they only need to ask questions in natural language to get real-time feedback. This feature improves the accessibility and user-friendliness of the data, attracting a wider range of users to access on-chain data.
In addition, the proxy service (agent) approach solves the problem of incompatible data standards. Since it is designed to have the ability to parse and process raw on-chain data, it can adapt to different data formats and standards. Therefore, developers do not need to reformat data from different sources, reducing their workload.
Of course, this is just a speculation about the future development trajectory of on-chain data. But in the field of technology, it is often these bold ideas and theories that drive revolutionary progress. We should remember that whether it is the invention of the wheel or the birth of blockchain, all major breakthroughs originate from someone’s assumption or “crazy” idea.
As we embrace change and uncertainty, we are also challenged to constantly expand the boundaries of possibilities. In this context, we envision a world where the combination of artificial intelligence, LLM, and blockchain will give birth to a more open and inclusive technological field.
Chainbase upholds this vision and is committed to realizing it.
Our mission at Chainbase is to build an open, friendly, transparent, and sustainable encrypted data infrastructure. Our goal is to simplify developers’ use of such data and eliminate the need for complex backend technology stack reconfiguration. In this way, we hope to usher in a future where technology not only serves users, but also empowers them.
However, I must clarify that this is not our roadmap. Instead, it is my personal reflection as a developer relations representative on the recent developments and progress of on-chain data in the community.
Like what you're reading? Subscribe to our top stories.
We will continue to update Gambling Chain; if you have any questions or suggestions, please contact us!
